
.AWS community-days 2020: Cost Optimization

A lecture for SRE, DevOps and FinOps teams on controlling AWS costs with optimizations and practical tips from practice.
Since the presentation is in german, here are the key topics written down in this blogpost
Download the PowerPoint here: AWS Community Days 2020 - cost-optimisation
AWS Lambda
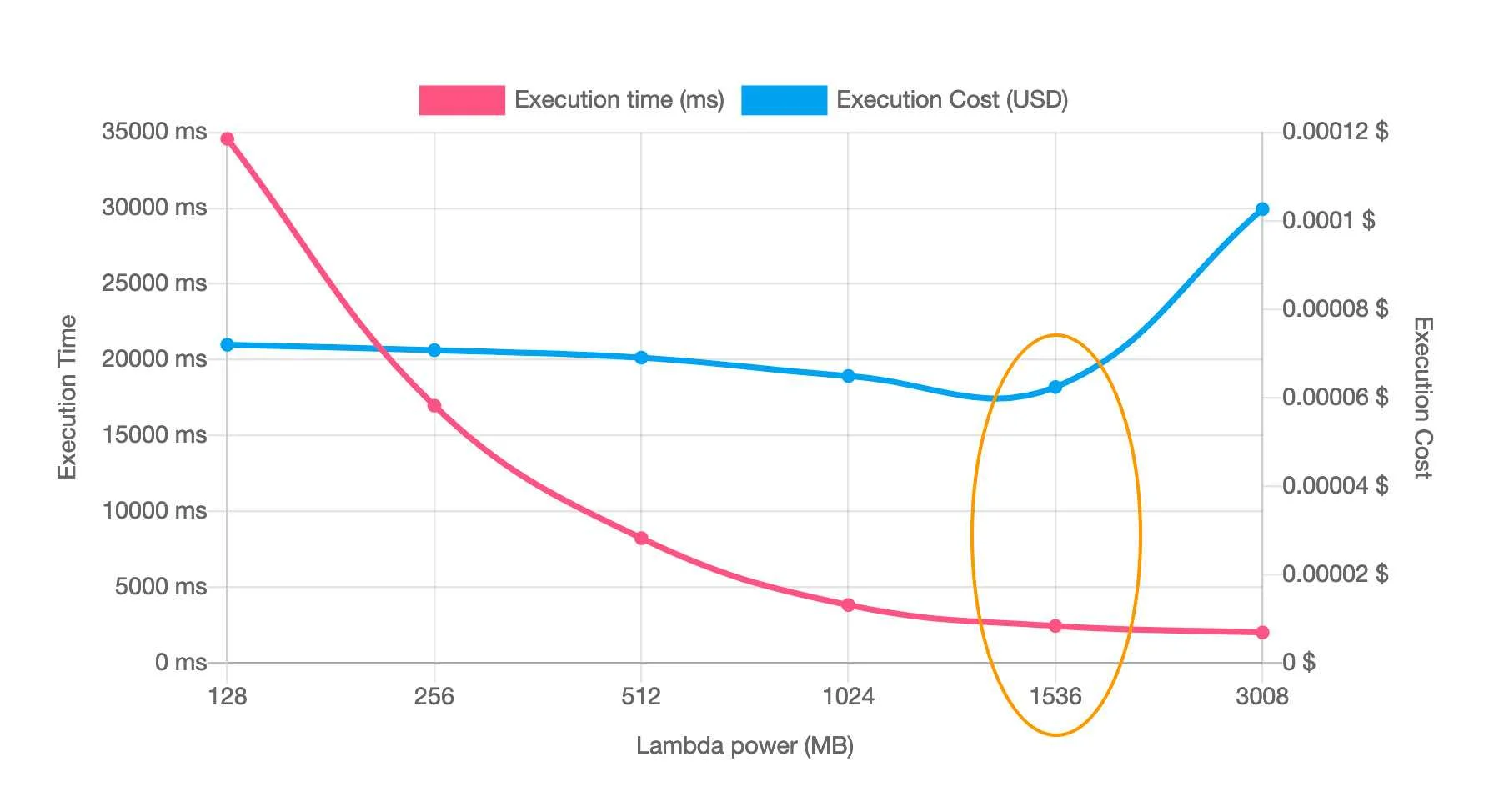
There are mainly 3 factors that make up your Lambda costs: the number of executions, the duration of each execution and the memory allocated to the function.
It is a good incentive to write efficient code in order to shorten the duration of each execution and therefore pay less for your Lambda. By automating, monitoring and eventually getting professional expertise you're already on a good path to FinDev.
Read more about Cutting down the cost on your Lambda.
Useful tool: AWS Lambda Power Tuning
AWS Kubernetes
4 Techniques to save money on EC2 for EKS
Auto-scaling, right sizing, down-scaling and optimizing instance price by replacing on-demand with spot instances are your best friends here.
Cluster Autoscaler
A requirement for cost-optimization in a Kubernetes cluster is having a Cluster Autoscaler running, it monitors the cluster for pods that are unable to run and detects nodes that have been underutilized.
Horizontal Pod Autoscaler (HPA)
After having a Cluster Autoscaler running you can be sure of the instance-hours being in line with the requirements of the pods in the cluster.
With the Horizontal Pod Autoscaler you are able to scale out or in the number of pods based on specific metrics, optimize pod hours and further optimize instance-hours but in order for it to work you have to ensure that the Kubernetes metrics server is deployed.
The combination of Cluster Autoscaler and Horizontal Pod Autoscaler is an effective way to keep EC2 Instance-hours tied as close as possible to actual utilization of the workloads running in the cluster.
Example HPA Configuration:
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadataL
name: nginx-ingress-controller
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: nginx-ingress-controller
minReplicas: 1
maxreplicas: 5
targetCPUUtilizationPercentage: 80
Right Size your Pods
Set the resources allocated for the containers in your pods. Requests should align as close as possible to the actual utilization. If the value is too low containers may throttle resources, if it's too high you're having unused resourced which you still pay for. "Slack costs" are described as when the actual utilization which is lower than the requested value.
Useful tool: Kube-resource-report
Down Scaling
Scale in and out the deployments based on time of day with the kube-downscaler in your cluster
A default uptime can configured via an environment variable
- DEFAULT_UPTIME = Mon-Fri 05:00-19:00 America/LosAngeles
- All deployments will have the size set to 0
- For all times outside of 5:00 AM - 7:00 PM, Monday - Friday
Individual namespaces and deployments can override their uptime
- Set a different update with the downscaler/uptime annotation
- Or disable it altogether with downscaler/exclude
Purchase options
Spot Instances have a significantly lower cost, for example a m5.large instance is consistently 50-60% less expensive than using On-Demand.
Run a Termination Handler tool, e.g.
Determine the termination workflow by...
- Identifying that a Spot Instance is about to be interrupted in two minutes
- Using the two-minute notification window to gracefully prepare the node for termination
- Tainting the node and cordoning it off to prevent new pods from being placed on it
- Draining connections on the running pods
AWS SageMaker
Right-sizing
Sagemaker offers various instance families. Each family is optimized for a different application which means they have to be analyzed to fit your usecase but remember that not all instance types are suitable for inference jobs.
AWS Elastic Inference
Another option to lower GPU instance- and inference cost is utilizing Elastic Inference which can achieve you up to 75% of cost-saving and is available for EC2 and SageMaker Notebook & Endpoints. The downside of this is a 10-15% slower performance.
Automatically scaling endpoints
With the automatic scaling for SageMaker you can add capacity or accelerated instances to your endpoints automatically when needed instead of monitoring the inference volume manually and changing endpoint configurations as a reaction to this. The endpoint adjusts the needed instances automatically to the actual workload.
Stop idle on-demand notebook instances
Certain SageMaker resources, for example instances for processing-training, tuning and batch-transformation are ephemeral, meaning SageMaker will start them automatically and stop them when the job is done.
Other resources, for example build-computing or hosting endpoints, are not ephemeral and the user has control over when to start or stop those resources. This knowledge of how unused resources can be identified or stopped can lead to a better cost-optimization.
This process can be automated with lifecycle configurations
A prerequisite for your Notebook instance is to have internet connectivity for fetching the Python script (autostop.py) from the public repository and some execution role permissions:
SageMaker:StopNotebookInstanceto stop the notebookSageMaker:DescribeNotebookInstanceto describe the notebook
Scheduling start and stop of notebook instances
Schedule your notebooks to start and stop at specific times. For example schedule notebooks of specific groups by using CloudWatch Events and Lambda functions
- Start your notebooks at 7:00 AM during weekdays
- Stop all of them at 9:00 PM
Here's a Lambda solution we published
Idle AWS SageMaker endpoint
You can provide machines as endpoints to test realtime-inference of the model, for example. What we witnessed often so far is these models stay operational afterwards inadvertently which leads to ongoing costs. For this reason it is advised to detect idle endpoints automatically and remove them in the next step. We also published a Lambda code with this solution on our globaldatanet Github repository.
How can we help you?
FinOps as a Service by globaldatanet
We support clients with cost-management & optimization in their environment, help teams with cost-visibility, accountability, cost-control and intelligence with our FinOps specialist team. So far 400+ Cost-Checks have been developed which we include in our analysis.
Our goal is to achieve full cost transparency with the latest cost optimizations.
DevOps as a Service by globaldatanet
We are highly skilled in DevOps, proven skills by the AWS DevOps Competency, and help teams with the continuous improvement of their software delivery process, optimizing deployment pipelines and DevSecOps as well. All this in a pay-as-you-go model instead of permanent rising costs.
Our Goal:
- Innovating faster while reducing risk
- Focus on building great software
Free DevOps Readiness Assessment
- Measure and understand your current software delivery capacity
- Understand the potential obstacles which currently exist
- Benchmark your future improvements on a predefined baseline
- Prioritize and change tracking ability
- Integrate these new ways of working into the cultural fabric










We use cookies on our website. Some of them are essential,while others help us to improve our online offer.
You can find more information in our Privacy policy