
.CDK Best Practices
In this post i want to show you my best practices while developing and deploying infrastructure using CDK. Let's start with a short intro about CDK. CDK - AWS Cloud Development Kit is a tool to manage AWS resources in a fully programmatic way. It is available in different popular programming languages like TypeScript, JavaScript, Python, C#/.NET and Java.
Key concepts
In the following picture you can see the anatomy of CDK.
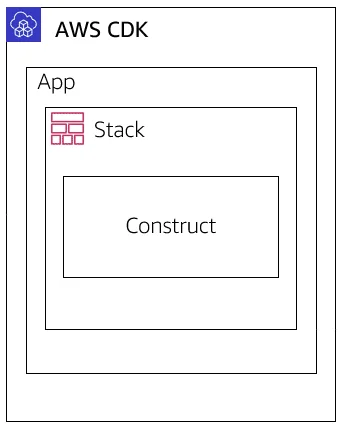
- Apps are the final artifact of code that define one or more Stacks.
- Stacks are equivalent to CloudFormation stacks and are made up of Constructs.
- Constructs define one or more concrete AWS resources, such as the S3 Bucket or your Lambda Function.
If you want to learn more about how to get started with CDK take a look at the AWS CDK Developer Guide or take a look at the CDK workshop.
Best Practices
Now let's jump into my Best Practices i am using on daily bases to build my automations with CDK. Just as a side note i am using CDK with Typescript.
Validation of your CDK APP variables
Whenever you want your user to pass information to your CDK app ensure to validate the variables. I want my users to pass the information via JSON files always so I can use typescript-json-schema for my app. Here is an example how my config-validator looks like.
import Ajv, {JSONSchemaType} from "ajv";
import {Config} from "../types/config";
import { resolve } from "path";
import * as TJS from "typescript-json-schema";
const settings: TJS.PartialArgs = {
required: true,
noExtraProps: true
};
const compilerOptions: TJS.CompilerOptions = {
strictNullChecks: true,
};
const program = TJS.getProgramFromFiles(
[resolve("lib/types/config.ts")],
compilerOptions
);
const schema = TJS.generateSchema(program, "Config", settings);
const ajv = new Ajv();
export const validate = ajv.compile(schema as JSONSchemaType<Config>);
Use Regex to check the CDK App variables
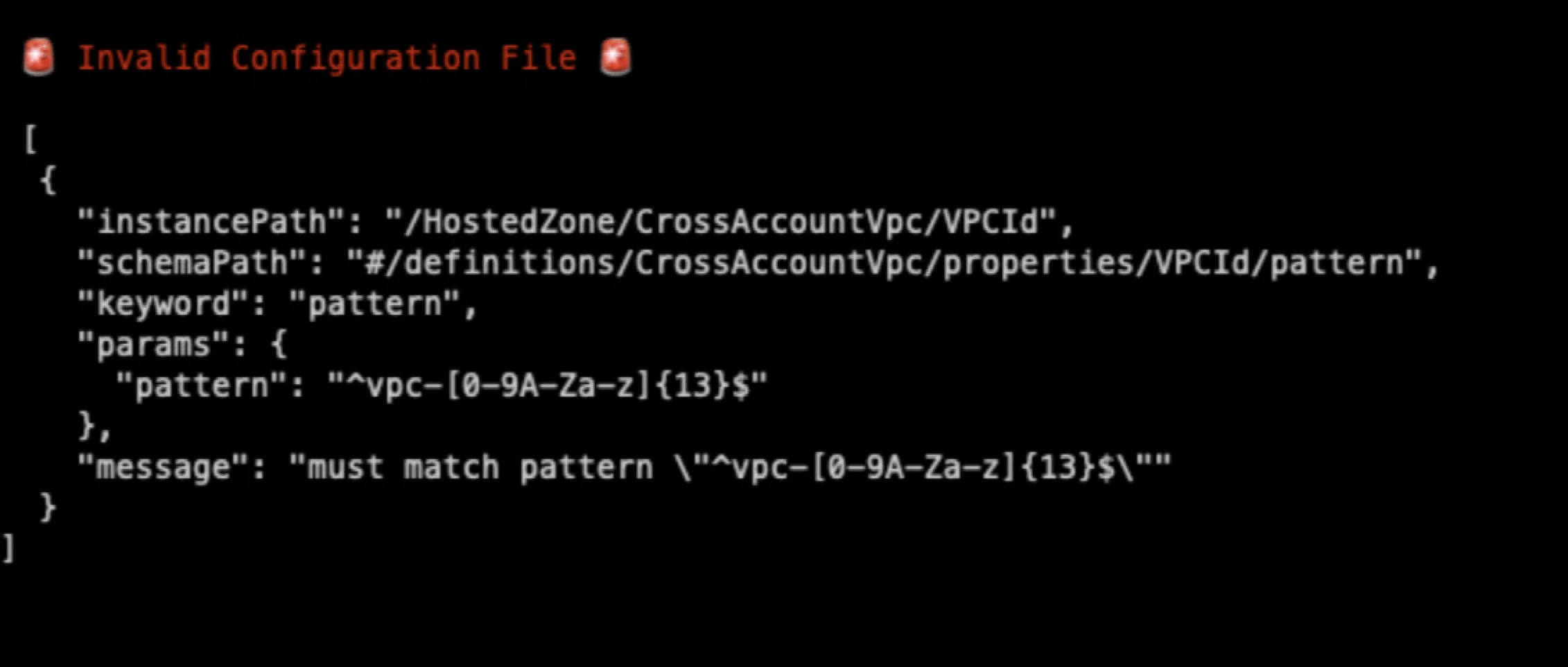
Whenever you need specific information in a variable like an AWS AccountId or VPCId you should use annotations with regex to validate the content of your variable before the deployment. Here is an example how your types could look like.
interface CrossAccountVpc{
/**
* @TJS-pattern "^vpc-[0-9A-Za-z]{13}$"
*/
readonly VPCId: string,
/**
* @TJS-pattern "^[0-9]{12}$"
*/
readonly AccountId: string,
}If the content of the variable is not correct the following error can be shown if you are using the schema validation:
Clean your cdk.out directory before deployment
When ever you want to deploy your cdk app to a new account or stage i can recommend you to clean your cdk.out directory before the next deployment. I am using taskfiles for deployment so I created a small clean task which will be invoked before my deployment task.
tasks:
deploy:
desc: Deploy Stack
cmds:
- task: clean
- task: cdkdeploy
clean:
desc: Clean CDK Out
cmds:
- rm -rf ./cdk.out
silent: true
cdkdeploy:
desc: CDK Deploy
cmds:
- cdk deploy --require-approval never {{.TAGS}} --strict
vars:
ACCOUNT:
sh: aws sts get-caller-identity |jq -r .Account
TAGS:
sh: cat tags/tags.json | jq -j '.[]|"--tags " + (.Key)+"="+(.Value)+" "'
silent: true
interactive: trueStructurize your app in multiple stacks
When building a CDK App which contains a lot of constructs it make sense to structurize your project and set up multiple stacks when creating the Infrastructure. Therefore it's good to know how you can reference resources across stacks in AWS CDK. If you want to learn how to do this - look at this blogpost.
Use Grants
AWS CDK help you to easily manage roles and security groups. The construct library grant() allows you to quick and simple create AWS Identity and Access Management roles granting access to one resource by another using minimally-scoped permissions. If you want to learn more about grants look at the aws cdk documentation.
Secure your CDK Resources
Whenever you deploy resources with CDK and manage them, secure them with SCPs (You can use service control policies to manage the security and permissions that are available to your organization's AWS accounts) so that they are not accidentally customized manually by others. CDK will otherwise lose its state and it will be difficult to repair it. Below you can see an example of an SCP to secure Route53 HostedZones from manual adjustments.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "DenyRoute53fornoneCDK",
"Effect": "Deny",
"Action": [
"route53:ChangeResourceRecordSets",
"route53:DeleteHostedZone",
"route53:DisassociateVPCFromHostedZone",
"route53:AssociateVPCFromHostedZone"
],
"Resource": [
"arn:aws:route53:::hostedzone/HOSTEDZONEID"
],
"Condition": {
"StringNotLike": {
"aws:PrincipalArn": "arn:aws:iam::AWSACCOUNTID:role/cdk-*"
}
}
}
]
}
If you want to learn more about SCPs look this blogpost.
Helpers Functions
If you are using helpers functions (SDK Calls) like Quota Checks, importing CloudFormation outputs as variables etc. I can recommend you to collect them in a file and import them into your bin / lib later. I call the file helpers.ts since I am using Typescript and but them under lib in to a own tools directory.
Renaming of logical IDs and resources
As you may know some AWS resources don't have any update mechanism using AWS CloudFormation like WAF Rule groups or VPC PrefixLists. If the resource is changing in an update and the API does not support this, a rollback can occur. To avoid this, you store the states of the corresponding resource in the outputs of the stack and query them with a helper function before an update, if the state of the resource changes you rename the logical ID and the resource name within the synth process and the resource can be updated successfully.
Here is an example:
You are deploying a WAF Rule with a capacity of 10 - within the next update your are changing the rule that the capacity changed to 15. This requires you to update the logical ID in the CloudFormation Stack + the resource name of the rule. To generate new IDs and resource names I am using a Date.now().toString(36); as automated addition for my names.











We use cookies on our website. Some of them are essential,while others help us to improve our online offer.
You can find more information in our Privacy policy