
.Customer Support Chatbot
Customer support is usually a lenghty and ardous process. Most of the issues are usually similar and a lot of them can be solved by searching through publically available documentation (FAQs for instance). But as a customer myself I know I don't want to look through documents I want my issues solved fast and with the least amount of effort involved, meaning I approach a customer support specialist.
So to prevent overworking your customer support and making sure your customers get the information they need a good solution is to provide a chatbot to assist as a first responder and level of support. This article will focus on providing a simple introduction to how you can achieve this using AWS services while following AI TRiSM principles.
Chatbot
Let's start with the fun stuff first: getting a chatbot up and running. Luckily we don't need to train our very own LLM from scratch but can tackle this using an existing LLM and something called Retrieval Augmented Generation (or RAG for short), both of which we can achieve through the use of AWS Bedrock.
RAG
Retrieval Augmented Generation is a cost effective way to optimize the output of an LLM, basically focusing an LLM on a specific set of information (for instance an organizations documentation and FAQs).
Creating a good knowledge base is probably the most important part of this process, because you are literally deciding what knowledge your bot possesses. This can be anything from internal training documents, public tutorials or FAQs, basically anyhing you would want a regular human answering these questions to know, and uploading it all to an S3 bucket for storage and processing.
For any sort of AI project to succeed we need data, and understanding your data is a crucial part of the technical and business sides of any AI projects.
After creating and uploading your knowledge base the next step would be to format and store the data in, let's call it an AI readable way. We achieve this by creating text embeddings and storing them in a vector database. To create the embeddings we are once again using AI through AWS Bedrock.
AWS Bedrock offers two models for embeddings, Titan Text and Cohere. They are both very powerful but Cohere has shown itself to be much better suited for a chatbot application considering that most tests show it's embeddings provide more detailed and precise responses. After this we need to choose the LLM that we will be chatting with. Once again AWS Bedrock offers numerous options, but considering we are expecting a certain level of complex reasoning it is best to choose Claude 3.0.
No matter your choice of model, your chatbot is now ready to answer questions by navigating to AWS Bedrock in the AWS Console, which brings us to one of the more important topics
AI Trust Risk and Security Management
We need to ensure that the information our chatbot provides is correct, precise and prevent it's misuse (tricking it into giving information it shouldn't or using it in any way other than what we intended). For this we defined the following success criteria:
- Making it clear when it does not have an answer instead of presenting false information
- Making it clear what it's role is and preventing the user from changing it
- Presenting a specific current response instead of generic or out of date information
- Creating responses from authorative sources only
- Presenting clear and precise responses without any terminology confusion
The first two can be achieved via prompt engineering. This is best done by creating a template that holds instruction how the LLM should act, what it's role is and what it's job is.
For instance:
You will be acting as an AI assistant named Globey created by the company globaldatanet.
Your goal is to answer questions about services globaldatanet offers.
If the question is not related to globaldatanet at all, kindly remind the user that your goal is to answer questions about globaldatanet.
You will be replying to users who are on the globaldatanet site and who will be confused if you don't respond in the character of Globey.
Here is the user's question:
Human: <question> {question} </question>
How do you respond to the user's question?This can be further enforced by creating rules for it:
# add this before the question is asked
Here are some important rules for the interaction:
- Always stay in character, as Globey, an AI assistant from globaldatanet
- If you are unsure how to respond, say “Sorry, I didn't understand that. Could you repeat the question?”Tips:
- Be as specific and direct as possible, and try not to be too clever
- Let the LLM know it can have some time to think about it's answer
The last 3 of these can be achieved by carefully choosing our data and creating our knowledge base to suit our needs. As such we need to make sure that no sensitive information (such as trade secrets or PII) are present in our knowledge base and that the documents placed in it are truthfull and up to date.
Infrastructure
Now that we have our model we can focus on letting our customers access it and ask questions to it, and here's a diagram that shows how we did it:
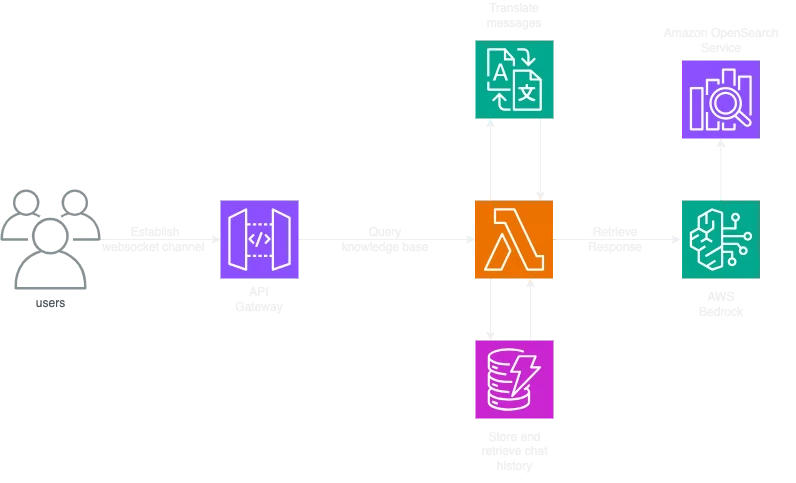
The most basic way to access our chatbot is via AWS API Gateway. As the primary use of this infrastructure is basically a chat app, we opted for using websockets instead of using a REST API. They let us create a channel to be used by the user and our backend to freely send messages back and forth and they also help us more easily manage chat history (more on this later)
After that we access our Lambda function which acts as the lynchpin between our users and our model. It's function can be explained as a translator that takes in text, makes it "AI readable" and then returns the response as Human readable. To achieve this we used the very powerful langchain library that helps us create embeddings from incoming messages and then sending them to AWS Bedrock. What happens next is, the Embedding model (Cohere) goes through our knowledge base in it's "AI readable" state (stored in a vector DB), and retrieves the documents closest to the question and finally adds them to the context of the question so that the LLM can more precisely answer the question.
A big part of the user experience when communicating with a bot is it's chat history, or basically it remembering what you talked about and how it answered and then using that as part of the context when answering your questions. This can also be achieved by using the very powerful langchain library, which has in-built functions to let us store and retrieve chat history in DynamoDB for easy access.
Our choice of using websockets helps us a lot with this, namely the fact that when you create a connection it recieves a unique ConnectID which we can use as a primary key to quickly and easily differentiate between users. Additionaly we can create custom logic so that our chat history is deleted when the user disconnects from the chat. Websockets allow us to do all this without maintaining session or cookie logic.
As a cherry on top when it comes to user experience, we want our system to be multilingual, meaning that users can use whatever language they want and get an answer in the same language, all the while the model can work with English (the language most models work best with). Unfortunately this is a bit hard to control through the LLM itself, so the best way to do this is to use AWS Translate to detect the dominant language of the message (it does this automatically via AWS Comprehend) for further processing, and then returning a response in the same language
Conclusion
Chatbots are a very powerful way to interact with your customers, and today it's easier than ever to create and maintain them through all sorts of managed services and some clever coding. But as always, with great power comes great responsibility, especially in the way you handle sensitive data.











We use cookies on our website. Some of them are essential,while others help us to improve our online offer.
You can find more information in our Privacy policy