
.Driving Business Innovation with NLP and LLMs - Part 1 - QA Models
In this series of articles, we're going to explore the powerful business benefits that come from leveraging large language models (LLMs) and natural language processing (NLP). We won’t be having a deep dive into super technical details like how BERT, ELECTRA & GPT architectures are, but rather focus on ways of leveraging these tools and technologies on delivering business value.
These technologies aren't just trending buzzwords. They're driving real change, enabling businesses to innovate faster, experiment better, and enhance their existing operations.
In the first part of this series we will go through Question Answering models and ways we can benefit from using them.
First things first, let's get familiar with some of the terms we'll be tossing around in this article.
Terminology
NLP
Natural language processing (NLP) is a machine learning technology that gives computers the ability to interpret, manipulate, and comprehend human language. __ AWS Documents
So basically, NLP enables computers to understand, interpret, and generate human language. It's like teaching computers our language, making interactions with them more intuitive and natural, and in doing so, it’s revolutionizing how we leverage technology in our day-to-day lives.
LLM
A large language model (LLM) is a computerized language model consisting of an artificial neural network with many parameters (tens of millions to billions), trained on large quantities of unlabeled text using self-supervised learning or semi-supervised learning. __ WikiPedia
So, in a nutshell, an LLM is like a super-smart parrot. It's been trained on lots of text and can spit out words that sound human-like. It doesn't understand language the way we do, but it does a good job of mimicking it.
What are Question-Answering (QA) Models?
One of the popular types of LLMs is Question-Answering. The way it works is that the model would require a context to understand, and a question to answer.
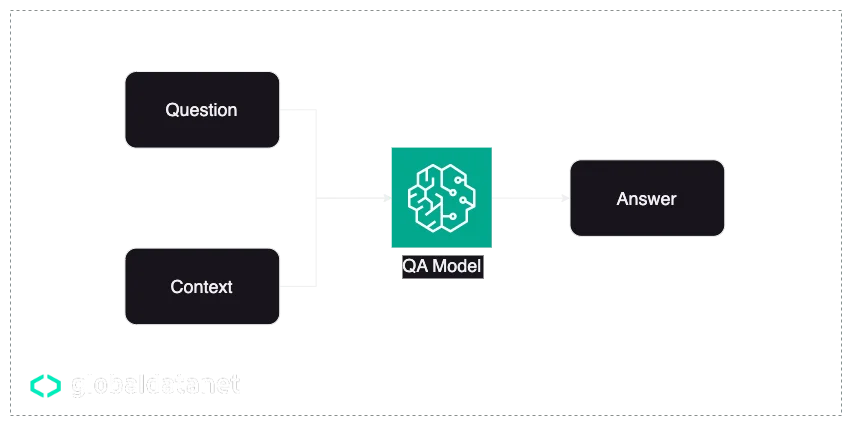
The way these models are trained is that they are provided with a substantial amount of data consisting of question, context, and answer data. This is known as supervised learning, where the model learns to correlate given contexts and questions with the correct responses, which is the basis of closed-domain QA. In this scenario, the model's ability to answer is limited to the context provided on model runtime.
On the other hand, for open-domain QA, models are trained in a more complex way. They need to comprehend a much broader set of data, even potentially the entire internet, to answer questions accurately. Although both open and closed-domain QA models would fall under the umbrella term of “Generative AI”, the open-domain ones represent the depth and breadth of Generative AI's potential in a more profound way.
Use Cases of QA Models
In this section we will go through some of the use cases of QA models and how we can benefit from them.
These are not all the ways we can benefit from QA models but they’re merely the tip of the iceberg!
Getting Answers From Videos
This one is my favorite. Here, a video can be anything, from a tech conference to a project planning meeting.
It has happened for me personally, that after some product meetings, I needed an answer to a question I remember being discussed.
At this point, it can be challenging to go through all of the recorded meetings to find that exact point discussed, while there can be a much more efficient solution to that problem.
Take a look at this simple architecture:
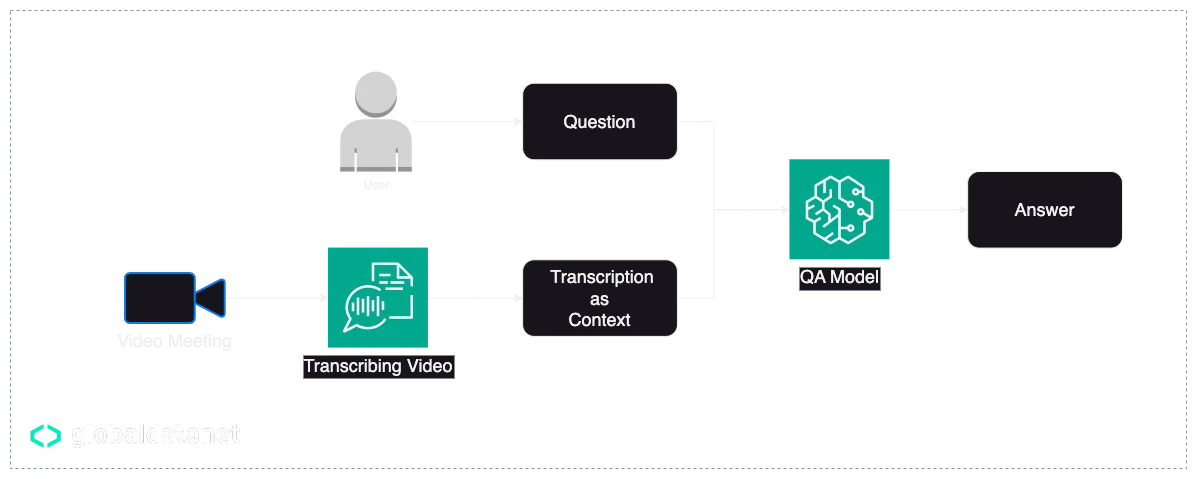
Here we are simply ingesting our video to Amazon Transcribe to get a meeting conversation as text, and then feeding that to the model as context for the question.
Please note that in this architecture we’re utilizing two different models. The first is AWS Transcribe, which fundamentally uses a speech-to-text model, and the second is the question-answering model which processes the transcribed text.
Getting Answers From Documents
A while ago we had a full-day globaldatanet workshop and our team’s name was NLP Wizards with the product of extracting data and answers from German rental contracts.

The idea came to life when we were discussing the challenges of understanding the details of rental contracts for tenants, a challenge that I personally faced before.
At first, we tried to solve the problem using Named Entity Recognition models like, ner-bert-german and ner-german-legal, but due to lack of a dataset to fine-tune the model we couldn’t reach a satisfying result.
That’s when we started using Textract Queries for getting the answers. Textract queries were introduced in April 2022 and it basically provides us with a fully serverless question-answering model endpoint.
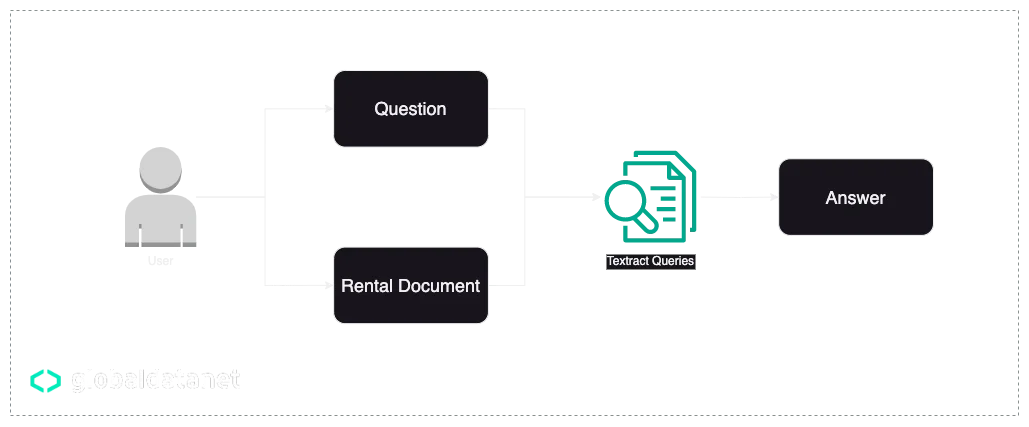
Lucky us Textract Queries supports the German language and it saved us some time finding a model and deploying it.
However, as mentioned in the next section, QA models come with certain limitations, and Textract is no exception. The maximum limit for Textract Queries is 10 pages, so you should keep that in mind.
Automated FAQ Generation & Customer Support Assistant
With the power of QA models we can automate the process of updating frequently asked questions, we can also assist our users using chatbots for specific contexts. This can reduce support costs and also help customers be able to get their answers based on their own provided documents and knowledge.
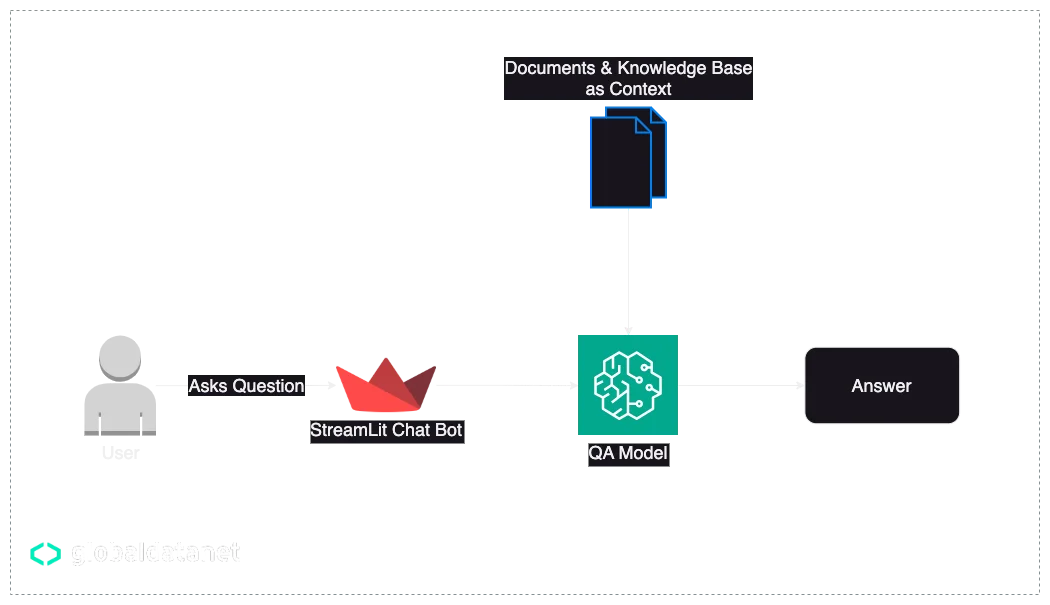
In this architecture, we have Streamlit for the client-side chatbot that the user interacts with, and the internal documents as pre-fed context.
Keep in mind that no solution is a Swiss army knife to suit every need. Depending on your domain, use case, and business you can make such a chatbot in many different ways, from Amazon Lex to Falcon and LLaMA.
Limitations
There are certain limitations to consider while using QA models for support chatbots:
Input Length Limitations: Many models have a maximum token limit, which puts an upper bound on the length of the input context. Even the Longformer model has a maximum length of 4096 tokens which would be somewhere around 8 pages of text.
You might wonder what about increasing the maximum length. The fact is that increasing the limit beyond the architecture's design is not possible without altering the model's architecture, which is a non-trivial task and in most cases can mean you’re asking the wrong question ;)
Context Relevance: The more relevant and concise the context, the more accurate the model's output is likely to be. Providing thousands of pages of context might actually reduce the model's performance because the relevant information could be lost among a lot of irrelevant information.
QA Models Worth Mentioning
There are a lot of models out there, trained for different purposes on different datasets. Here I want to mention some of them that I had the chance to try.
Multilingual
deutsche-telekom/bert-multi-english-german-squad2
The nice thing about this model is that it’s German/English Bilingual, you can give it a German context and ask English questions. I tried it for the NLP Wizards idea mentioned earlier, and it could give a proper German answer to an English question with limited context on rental contract context for security deposit cost and monthly rent.
deepset/xlm-roberta-large-squad2
This one is also multilingual but it includes many more languages.
English
In short, RoBERTa is a retrained, rearchitected, and optimized child of BERT, the first model mentioned above is based on BERT, and this one is based on RoBERTa.
You might have noticed that they all have squad2 postfix, and the reason is that they’re all trained on the SQuAD2.0 dataset. So they have different base models but all trained on the same dataset, or a translated variation of it like German deQuAD 2.0.
German
deutsche-telekom/electra-base-de-squad2
Yet, another model fine-tuned by Telekom for the German language specifically.
Conclusion
In wrapping up part one of our series, we've shed some light on the power of NLP and LLMs, especially QA models.
These sophisticated tools provide a breakthrough in how we interact with data and offer numerous opportunities to innovate and improve business processes.
I will announce the next parts of the series on my LinkedIn, stay tuned as we explore further into these fascinating technologies.











We use cookies on our website. Some of them are essential,while others help us to improve our online offer.
You can find more information in our Privacy policy