
.Intelligent Document Processing using AWS
Many big companies depend on the processing of large batches of documents daily. Packages, medical documents, receipts, you name it. For example, a doctor would want to have a patient's report scanned and to see all the data from the report in an application his ordination uses to manage patients.
In the past, this process was first done manually, but with significant technological advancement, today we have trained algorithms which scan, read and understand both paper and digital documents. This is called Intelligent Document Processing.
In order to clarify the whole process, we’ll briefly explain the services we are going to use and we’ll go through the flow step by step.
Here's a diagram to give us a picture of what we are about to go through:
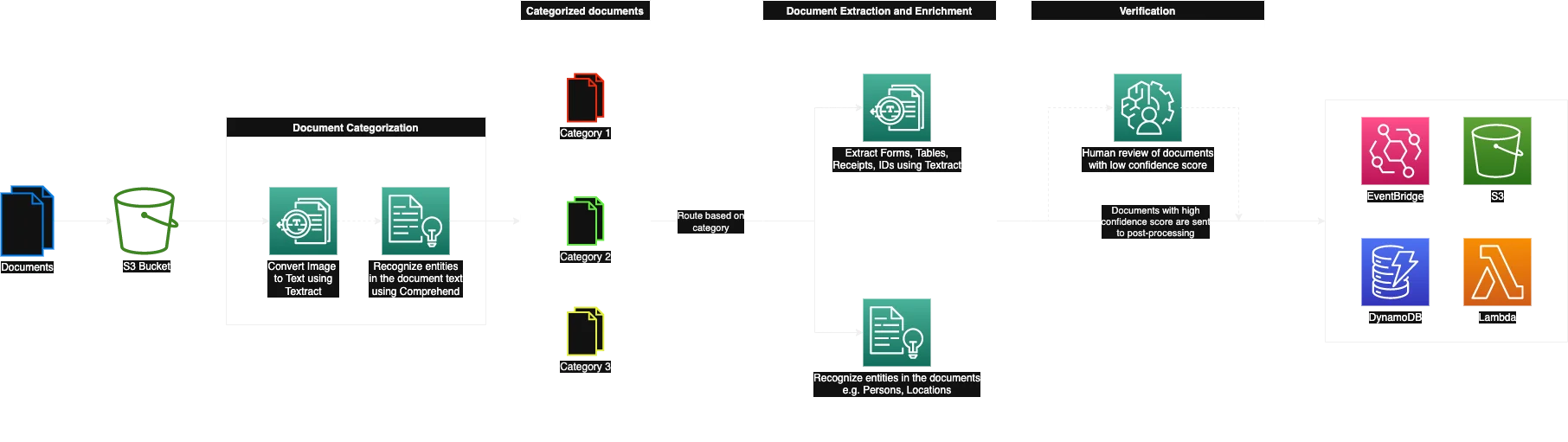
AWS Services
- S3 - Storage
- Textract - Optical Character Recognition (OCR)
- Comprehend - Natural Language Processing (NLP)
- Comprehend Medical - Specifically trained NLP service for medicine
- SageMaker - Machine Learning (ML) service which provides the infrastructure and basic training algorithms through UI called SageMaker Studio
- Augmented AI - Human verification through SageMaker Studio
Document ingestion
In order to process the documents, we first have to get them into our system. In our example, we'll be using AWS S3 to store our docs.
The usual types of docs that go through these processes are personal documents (IDs, passports, driver’s licenses…), medical documents, receipts…
Document categorization
When we get a document we first run it through Textract. Here we will use it to extract the text from our document so we can send it further to Comprehend to determine its category.
To classify our documents confidently, we train our custom Comprehend model. Let’s say our system can receive IDs and receipts. We would then feed our custom model with 150 receipt examples and 150 ID examples, both of which we will label respectively, in order to train it. We train it using SageMaker which provides us with the proper ML infrastructure.
We then use this trained model to tag all the documents we receive with an appropriate category. Sometimes Comprehend may not be confident about the category - meaning that the confidence score of the document is lower than expected (usually that would be lower than 0.8). That’s why we have the verification step which we’ll explain later.
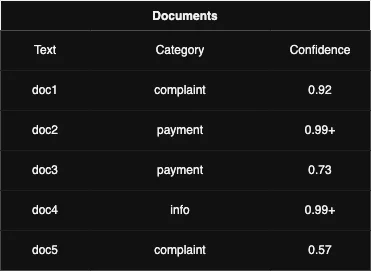
In the example above, we can see some documents after the categorization is done. We can see that doc3 and doc5 do not satisfy our confidence threshold of 0.8. These 2 would be sent for human review after the extraction and enrichment are done.
Extraction and enrichment
- Extraction - Textract
- Detect text in images
- Identity documents
- Input documents
- Invoices and receipts
- Forms
- Enrichment - Comprehend
- Entity recognition - People, places, organizations, locations…
- Personally identifiable information (PII) - Credit card details, addresses…
- Redaction - Hide sensitive information in the document (PII usually)
Textract receipt example:

Results:
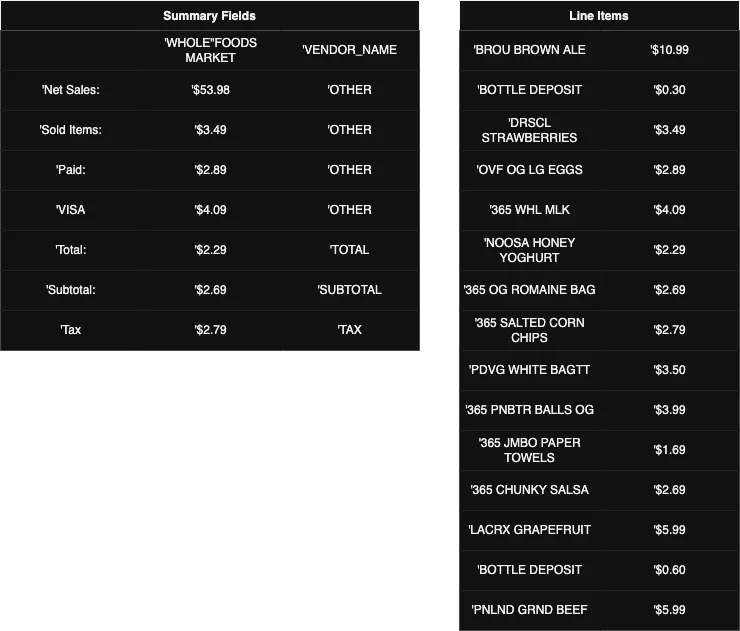
This Textract example can be executed in AWS Console by navigating to Amazon Textract > Demos > Expense Demo. Examples for other doc types can also be seen there.
Comprehend bank email example:
“Hello Maria, I am Nick. Your AnyCompany Financial Services, LLC credit card account 1111-0000-1111-0008 has a minimum payment of $24.53 that is due by July 31st. Based on your autopay settings, we will withdraw your payment on the due date from your bank account number XXXXXX1111 with the routing number XXXXX0000.”
From this text, comprehend can recognize entities, key phrases, languages, PII, sentiment and syntax.
We’ll focus on entities and PII.
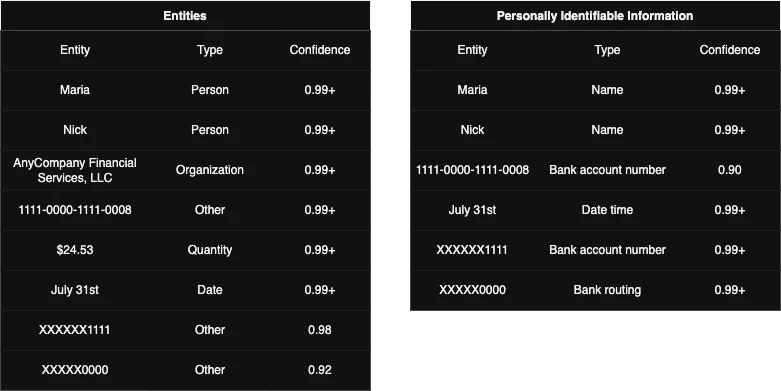
In the results, we can see how Comprehend has classified our data and which confidence score is assigned.
We can also redact (hide) the sensitive data using Comprehend. In our example above, it would come in pretty handy to hide the bank data in the final version of the document which would be accessible in our app after the document leaves our pipeline.
This is how our text would be displayed after the redaction:

The Comprehend demo is also available in AWS Console. While you are at it, you can also check out Comprehend Medical example. Comprehend developers have created this separate service exclusively for medical purposes, it is very insightful but we are not covering it in this blog since we are not medically literate :)
Verification
We determine if the document is valid for business usage depending on the Comprehend confidence score. Either the categorization one or the enrichment one.
In our SageMaker studio, we determine our confidence threshold. Let’s say that’s 80% (0.8). When the previous steps are done, all documents with a confidence score lower than the threshold we’ve set will be sent for human review. There our reviewers can compare the original document and the Comprehend results, make the required adjustments and forward the doc to post-processing or straight to its destination (S3, EventBridge, DB…).
Real use case scenario
Let’s try showing IDP in a real-life scenario. Imagine that we are running a fast food chain. We have, let’s say, 100 restaurants in our franchise. Every restaurant sends documents daily to our management app.
We have 2 types of documents:
- A scanned report which consists of a written report and a table with all of the expenses from that day
- A scanned incident form
Our employee responsible for these documents has to go through every report and sort it accordingly. But 10 years ago, not today. Today we can use IDP to automate this process.
We train our Comprehend classification and entity recognition models by feeding them with the past docs (reports, incidents).
Let’s say that we want to have a list of all daily expenses from the day and that we want key points from a written part of the report as well ( name of the manager, number of employees in the shift… ).
In this case, Textract would give us our table data with expenses and Comprehend would understand the written part and recognize the name of the manager, number of employees, etc.
Then that document data would be stored in our DynamoDB and the image (scan) itself would be stored in S3. This way, we can fetch the original document from S3 and all the enriched data from DynamoDB for the user to view.
In our UI, this is how we display the final version of the doc:
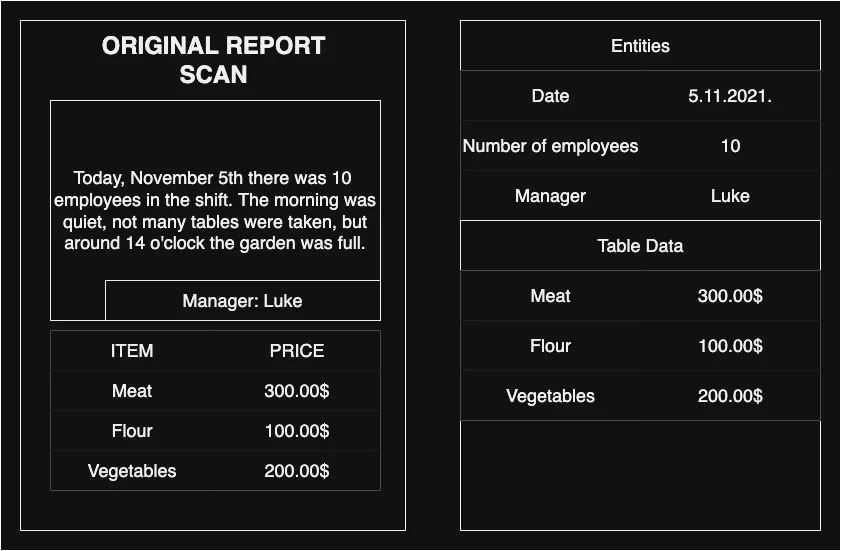
As you can see our design is the most modern and advanced there is 😅
On the left side of the page is the original document, while on the right side we have highlighted the enriched and extracted data.
Now our employees do not have to look at a bunch of scans and type in the data manually, they can just see it in the app.
We hope we've brought IDP closer to you in a clear and interesting way.
In case you find this topic interesting , fell free to check out the post. from my colleague Nikita. There can find a great business point of view on Intelligent Document Processing 👀
To sign off - there’s a myth that people invented IDP so they could extend their lunch and cigarette breaks because they wouldn’t have to go through a bunch of docs manually anymore 😆











We use cookies on our website. Some of them are essential,while others help us to improve our online offer.
You can find more information in our Privacy policy